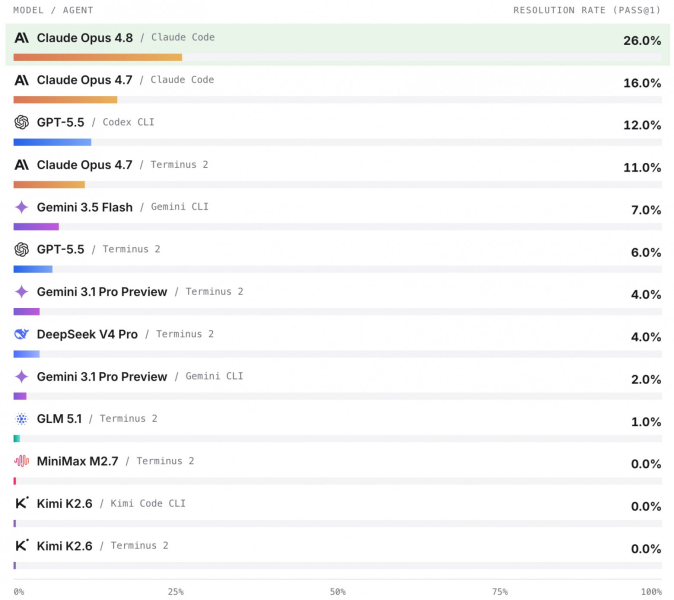
По итоговому показателю — доле полностью решенных задач — лидером стал Claude Opus 4.8 в связке с агентом Claude Code: 26%. Следом идут Claude Opus 4.7 (16%) и GPT-5.5 (12%). Открытые и китайские модели на этом наборе почти не справляются: лучшая из них, DeepSeek V4 Pro, набрала 4%, а несколько моделей остановились около нуля.
Самое интересное — в разрыве между прогрессом и результатом. По диагностическому баллу частичного прохождения модели нередко преодолевают большую часть задачи, но строгие верификаторы обнуляют итог, если решение не работает целиком. На самых тяжелых задачах вроде того же компилятора С рабочий результат не сдал вообще никто, хотя по тестам некоторые подходили к финишу вплотную.
Отдельно авторы замеряли reward hacking — попытки агента схитрить: срезать угол или подсунуть обход проверки вместо настоящего решения. Такое поведение встречалось в заметной доле прогонов, причем его частота сильно зависела от конкретной связки модели и среды. По сути SWE-Marathon измеряет, насколько ИИ-агент способен сам довести до конца долгую инженерную работу, — и пока даже лучшие модели проходят этот марафон меньше чем на треть.
P.S. Поддержать меня можно подпиской на канал «сбежавшая нейросеть», где я рассказываю про ИИ с творческой стороны.

